TL;DR:
- Node.js v0.8 позволяет обрабатывать 1 млн одновременных HTTP Comet соединений на Intel Core i7 Quad/16 Gb RAM практически без дополнительных настроек.
- На 1 соединение тратится чуть больше 10 Kb памяти (4.1 Kb Javascript Heap + 2.2 Kb Node.js Native + 3.8 Kb Kernel)..
- V8 Garbage Collector не рассчитан на управление > ~500Mb памяти. При превышении нужно переходить на альтернативный режим сборки мусора, иначе «отзывчивость» сервера сильно уменьшается.
- Подобный опыт можно (и нужно!) без особых затрат повторить самому (см. под катом).
Введение
В зарубежных блогах было рассмотрено несколько тестов максимального количества одновременных соединений, от классического A Million User Comet Applicaction with Mochiweb/Erlang, до совсем недавнего Node.js w/250k concurrent connections. Чего мне хотелось бы добиться в моём тесте — так это повторяемости. Чтобы другие могли без особых проблем повторить и получить свои результаты тестирования. Весь код, который был использован в тестах, выложен на github: сервер и клиент, добро пожаловать.
Сервер
1. Железо
Безусловно, вам понадобится Dedicated Server для проведения подобных тестов. Закажите его у вашего любимого хостера или используйте уже существующий. Я использовал Hetzner EX4 (Core i7-2600 Quad, 16Gb RAM), он достаточно дешевый и мощный.
2. Операционная система
Я использую Ubuntu 12.04 LTS. Возможно, мой тест можно будет использовать и в других Linux-ах, с небольшими изменениями. Скорее всего такое не прокатит на других OS. В сети достаточно много рассказано про настройку Linux под большое кол-во соединений. Что радует, практически ничего из этого не понадобилось:
#/etc/security/limits.conf
# Увеличиваем лимит дескрипторов файлов (на каждое соединение нужно по одному).
* - nofile 1048576
#/etc/sysctl.conf
# Если используете netfilter/iptables, увеличить лимит нужно и здесь:
net.ipv4.netfilter.ip_conntrack_max = 1048576
3. Код для Node.js
Во всех тестах используется Node.js v0.8.3.
Используем стандартный модуль cluster для распределения нагрузки на несколько процессов (по количеству ядер). Отключаем алгоритм Нагла.
// Server.js (упрощённый)
var cluster = require('cluster');
var config = {
numWorkers: require('os').cpus().length,
};
cluster.setupMaster({
exec: "worker.js"
});
// Fork workers as needed.
for (var i = 0; i < config.numWorkers; i++)
cluster.fork()
// Worker.js (упрощённый)
var server = require('http').createServer();
var config = {...};
server.on('connection', function(socket) {
socket.setNoDelay(); // Отключаем алгоритм Нагла.
});
var connections = 0;
server.on('request', function(req, res) {
connections++;
// Каждое соединение получает'пинг' каждые 20 сек
// = 50к сообщений в секунду на 1 млн соединений
var pingInterval = setInterval(function() {
res.write('ping');
}, 20*1000);
res.writeHead(200);
res.write("Welcome!");
res.on('close', function() {
connections--;
clearInterval(pingInterval);
pingInterval = undefined;
});
});
server.listen(config.port);
Для удобства наблюдения за происходящим я добавил отслеживание и отображение множества системных параметров в терминале, а также их логгирование. Запустить это чудо интерактивности у себя на сервере можно следующим образом:
git clone git://github.com/ashtuchkin/node-millenium.git
cd node-millenium
# По умолчанию слушаем порт 8888.
node server.js
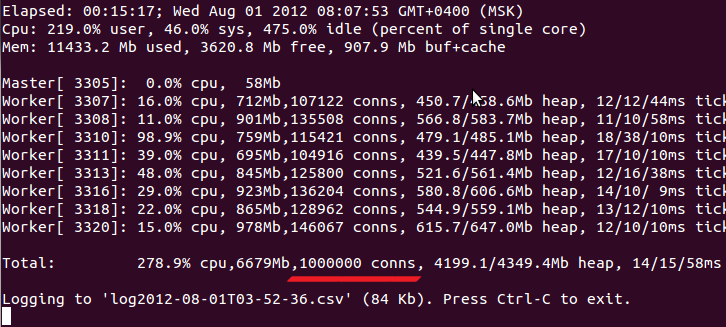
Получаем картинку похожую на эту:

Тут надо отметить следующее:
- Проценты загрузки процессора везде выдаются с учетом кол-ва ядер. Т.е. на 4-ядерном процессоре максимальная загрузка — 400%.
- В 'used' память не входит buf+cache. Т.е. должно быть used+free+(buf+cache) = всего памяти на сервере.
- Для каждого процесса выводится его pid, доля загрузки процессора (user+sys), RSS-память, кол-во соединений, heapUsed/heapTotal по показаниям os.memoryUsage(), три измерения «отзывчивости» процесса (ticks, см. ниже).
Что же это за «отзывчивость» (responsiveness) процесса? Условно, это сколько нужно будет ждать событию перед тем, как его обработает Event Loop Node.js. Этот параметр принципиален в приложениях, рассчитывающих на хоть-какой-нибудь real-time, но его достаточно сложно подсчитать.
Измерять его будем следующим образом:
// Просим Node.js вызывать нас ровно раз в 10 мс и запоминаем время вызовов.
var ticks = [];
setInterval(function() {
ticks.push(Date.now());
}, 10);
// Раз в секунду обрабатываем.
setInterval(function() {
// 1. Вычисляем промежутки между тиками: ticks[i] = ticks[i+1]-ticks[i]
// 2. Затем в полученном массиве ticks вычисляем среднее (tick-avg), 90-й процентиль и максимум (tick-max).
// 3. Выводим в приведенном порядке на экран и в лог.
ticks.length=0;
}, 1000);
Хочу отдельно отметить, что интервал замера 10 мс был выбран как баланс между погрешностью и доп. нагрузкой системы. Если выводится 10/10/10ms — это не значит, что на обработку каждого события Node.js тратит по 10 мс. Это значит, что при сетке измерения 10 мс Event Loop каждый раз свободен и готов обрабатывать сразу любое поступившее событие, что означает, что среднее время обработки событий гораздо ниже. Если же вступает в действие Garbage Collector, или длинные операции, то мы это мгновенно увидим и зафиксируем.
Лог ведется в формате CSV, где раз в секунду отмечаются все агрегатные статистики системы (см. список на гитхабе).
Клиенты
Как это ни странно, обеспечить необходимую нагрузку было сложнее, чем создать сервер. Дело в том, что TCP-соединение уникально определяется четверкой [source ip, source port, dest ip, dest port], таким образом с одной машины на 1 порт сервера можно создать не более 64 тыс одновременных соединений (по количеству source ports). Можно было бы создать 16 сетевых интерфейсов с разными IP, как было описано здесь, но это сложно когда машинка стоит у хостера.
В результате, было принято решение использовать Amazon EC2 Micro Instances по 2 цента в час. Было выяснено, что такая машинка в силу ограничений по процессору и, особенно, памяти, стабильно держит около 25 тыс. соединений. Таким образом, 40 запущенных инстансов обеспечат нам 1 млн соединений и будут стоить 0.8$ в час. Вполне приемлемо.
Отдельно нужно сказать, что по умолчанию Amazon не даст вам поднять более чем ~20 инстансов в одном регионе. Можно либо оставить заявку на увеличение этого предела, либо поднимать инстансы в нескольких регионах. Я выбрал последнее.
Сначала я настроил одну машину и скопировал её 40 раз используя механизм создания Custom AMI — это легко сделать через веб-интерфейс. Однако, это оказалось слишком сложно в поддержке и неуправляемо, поэтому я перешел на другой механизм: User Data и Cloud Init.
Вкратце, это работает так: используются стандартные образы Ubuntu (в каждом регионе они разные) и при старте инстанса в качестве параметра указывается скрипт. Он исполняется на инстансе сразу после его поднятия. В этом скрипте я устанавливаю на голую систему Node.js, записываю необходимые файлы и запускаю ноду, которая слушает определенный порт. Далее, по этому порту можно узнать статус сервера, а также дать ему команды, например, сколько соединений установить с каким ip адресом. Время от команды до работающего «дрона» — около 2-х минут.
Что приятно — код клиента может редактироваться перед каждым запуском инстансов.
Попробовать сами вы можете с помощью проекта ec2-fleet и следующих команд:
git clone git://github.com/ashtuchkin/ec2-fleet.git
cd ec2-fleet
# Инсталлируем необходимые внешние модули
npm install
# Вставьте свои параметры accessKeyId, accessKeySecret от вашего аккаунта в Amazon.
# https://portal.aws.amazon.com/gp/aws/securityCredentials
# Также, выберите регионы в которые будут запускаться инстансы (не менее трёх)
# Важно! Во всех этих регионах вам нужно будет подредактировать Security Group 'default' и открыть
# TCP порт 8889 для source 0.0.0.0/0 - через него мы будем управлять нашими инстансами.
nano aws-config.json
# Стартуем, например, 10 инстансов равномерно по регионам.
# Все инстансы помечаются специальным тегом. Далее, мы работаем только с ними.
./aws.js start 10
# Смотрим статус в отдельном терминале (похоже на top). Ждем пока все не стартуют.
./aws.js status
# Ставим цель (предполагается, что это именно тот сервер, который мы тестируем)
./aws.js set host <ip>
# Каждый дрон устанавливает по 1000 соединений
./aws.js set n 1000
# Максимальное рекомендуемое значение - 25000 соединений
./aws.js set n 25000
# Рестарт ноды на всех серверах. Рекомендуется делать между тестами.
./aws.js set restart 1
# После тестов удаляем все наши инстансы. Другие - не трогаем.
./aws.js stop all
Тесты
Ну чтож, начнём тестирование. Здесь и в следующих тестах будем делать 1 млн соединений, 50 тыс сообщений в секунду на всех. Node.js версии v0.8.3. Обработка будет вестись в 8 процессах («воркерах») по кол-ву ядер сервера.
node server.js
В первом тесте мы будем запускать node.js без дополнительных флагов, в самой что ни на есть стандартной конфигурации. Начинаем первый тест (все картинки кликабельны):

На всех графиках черной пунктирной линией обозначается кол-во соединений, с максимальным значением в 1 млн. По горизонтали — секунды от начала теста, вертикальные линии отмечают минуты. Графики памяти показывают: Total — общее кол-во занятой памяти (напомню, тестирование проводилось на сервере с общим объемом памяти 16 Gb), Total netto — увеличение Total по сравнению с первой секундой (был введён т.к. на этой машине крутится еще несколько моих проектов, суммарно они занимают ~1.3 Gb), RSS mem, JS Heap Total, JS Heap Used — суммарное значение RSS (ссылка), JS Heap Total, JS Heap Used всех процессов node.js.
Визуально величина серой области обозначает объём памяти, выделенных ядром, желтая область — нативных структур node.js, зелёная — JS Heap.
Как видно, Total netto в пике составляет 10 Gb и стабильно держится. После эксперимента все параметры возвращаются практически в исходные значения кроме нативных структур node.js. Вернёмся к ним ниже.
Загрузка процессора на том же тесте:

Здесь всё проще — 8 ядер = 800%. Total — общая загрузка, CPU (практически совпадает с Total) — суммарная загрузка процессов node.js, User, Sys — общая загрузка в User mode и ядре соответственно. Линии сглажены скользящим средним по 10 секунд.
Вот этот график, честно говоря, меня разочаровал. Загрузка слишком большая, причём непонятно на что она тратится. Приём соединений проходил нормально, порядка 5-7 тыс. соединений в секунду, видимо, этот сценарий хорошо оптимизирован. Однако, гораздо большую нагрузку создает отсоединение, особенно большими партиями (на графике ок. 3 минут 800% загрузки когда я попытался порвать сразу 400 тыс соединений).
Посмотрим, как ведет себя Event Loop:

На этом графике показаны средние значения tick-avg по 8 воркерам (к сожалению, tick-max не удалось восстановить из-за бага). Шкала логарифмическая, чтобы отразить большие колебания. Желтой линией отображается скользящее среднее по 20 секундам.
Как видно, в среднем при 1 млн соединений к Event Loop получается получить доступ всего 10 раз в секунду (желтая линия ~100 мс). Это просто никуда не годится. При отключении 400 тыс соединений среднее время обработки события возрастает до 400 мс.
После использования гугла по назначению и проведения нескольких опытов меньшего масштаба, было выяснено, что основную часть нагрузки вызывает Garbage Collector, который пытается довольно часто собирать лишнюю память, используя «тяжёлый» алгоритм Mark&Sweep (у V8 их два — есть ещё «легкий» Scavenge). Ответственность за такое поведение лежит где-то на границе между Node.js и V8, и связана с механизмом Idle Notification. Вкратце — это сигнал для V8, что работа сейчас не выполняется и есть время подчистить мусор, которым Node.js злоупотребляет, особенно если JS HeapTotal > 128Mb.
node --nouse-idle-notification server.js
К счастью, мы можем выключить этот сигнал добавив флаг "--nouse-idle-notification". Посмотрим что нам это даст во втором тесте:

Во-первых, можно отметить, что потребление памяти увеличилось на 1 Гб (10%) и стабилизировалось где-то через 5 минут после последнего соединения, что, в общем-то неплохо. Также, виден «пилообразный» характер графика. Почему?
Давайте посмотрим график потребления памяти одного воркера в упрощенном тесте:

Теперь понятно — примерно раз в 5 минут происходит сборка мусора в каждом воркере, формируя «пилу» в графике суммарной памяти.
Смотрим процессор и Event Loop:


Ну вот, так гораздо лучше! 1 млн. соединений нагружают от 2 до 3 ядер из 8.
Теперь посмотрим хорошо ли справляется Garbage Collector без IdleNotification в третьем тесте:

Из этого графика видно во-первых, что желтая область (Node.js native structures) всё таки не утекла, а переиспользуется. Во-вторых, сборка мусора могла бы быть и получше.
node --nouse-idle-notification --expose-gc server.js
Чтож, берём сборку мусора в свои руки. Запускаем node.js с флагом "--expose-gc" и вызываем gc(); раз в минуту в четвертом тесте:



Чтож, неплохо. Память высвобождается достаточно резво, процессор под контролем, но раз в минуту у нас есть всплески tick-avg. Думаю, это хороший компромисс.
Что дальше?
Во-первых, необходимо подтверждение результатов независимым тестированием. Я сделал всё, чтобы это было просто. Пожалуйста, если у вас простаивает хорошая машинка, попробуйте сами проделать мой путь — это очень интересно.
Во-вторых, ясно, что этот benchmark далёк от реальности. В качестве интересного реального применения хорошо было бы построить аналог jabber-сервера и потестить его на таких же объемах.
В любом случае, надеюсь, что и текущий фреймворк поможет разработчикам Node.js и V8 в дальнейшей оптимизации.
В-третьих, нужно провести ещё эксперименты для выяснения:
- На что влияет включение/отключение алгоритма Нагла (socket.setNoDelay()).
- Одно сообщение в 20 секунд на соединение — достаточно мало. Какое количество сообщений в секунду выдержит сервер? Возможно, в этом будет ограничение на реальных проектах.
- Можно более точно определить выделение памяти ядром на сокеты используя /proc/sockstat.
- Почему не освобождается желтая область (Node.js native)? Что это? Как это можно исправить?
- Почему закрытие сокетов нагружает процессор гораздо больше, чем их открытие?
- Попробовать поиграться ещё с настройками ядра для TCP, а также выключить модуль netfilter/conntrack/iptables, может это положительно скажется на памяти.
- Используя метод с 40 инстансами AWS попробовать нагрузить сервера с другими технологиями — Erlang, Java NIO, Twisted и т.п. Сравнить характеристики.
- Как быстро происходит межпроцессное взаимодействие? Можно ли передавать открытый дескриптор между процессами, группируя их по комнатам, для локализации взаимодействия между клиентами? Это сильно поможет в реальном проекте.
Ну и в-четвертых, shameless plug — если вам интересно работать на Node.js в реальных проектах — напишите мне на ashtuchkin@gmail.com, я как раз сейчас ищу людей в команду.
Если вы ведёте свой блог, микроблог, либо участвуете в какой-то популярной социальной сети, то вы можете быстро поделиться данной заметкой со своими друзьями и посетителями. Для этого воспользуйтесь предлагаемыми ниже кнопками:
Блог: http://romanlovetext.blogspot.com/