
Предисловие
Всякий серьёзный разработчик рано или поздно сталкивается с проблемой реализации в своём творении неких элементов искусственного интеллекта. За исключением ряда логических головоломок и некоторых аркад, искусственный интеллект есть то, что предоставляет игроку необходимый для получения удовольствия от игры элемент состязательности.
В этой статье я хотел бы представить довольно простое и изящное решение в области создания искусственного интеллекта для Ваших игр. Я умышленно не привожу в статье конкретных примеров кода, делая упор именно на теоретическую составляющую, так как средства, о которых пойдёт речь ниже, могут быть без особых затруднений применены к весьма широкому спектру задач.
Статья предназначена в первую очередь для новичков в игростроении, ещё только размышляющих над реализацией схем работы AI (здесь и далее – англ. artifical intelligence – искусственный интеллект) в своих играх, но может быть полезна и опытным разработчикам.
Вступление
Какими методами обычно реализуется AI в компьютерных играх? Как ни странно, несмотря на значительное развитие отрасли со времени появления первых игр, в которых игроку приходилось сталкиваться с некой принимающей решения враждебной ему силой, основные схемы функционирования искусственного интеллекта остались принципиально неизменными.
Наиболее простая, классическая схема функционирования логики компьютерного оппонента – это система ветвлений. Поясню свою мысль на примере такого псевдокода с C-образным синтаксисом:
(для незнакомых с этим синтаксисом - через точку тут указывается обращение к какому-либо свойству или методу объекта)
Подпрограмма Идём_В_Атаку(<набор параметров>) { Если (персонаж.под_обстрелом) { Если (персонаж.не_вижу_врага) персонаж.осмотреться(<параметры>); персонаж.искать_укрытия(<параметры>); Если (персонаж.вижу_укрытия_рядом) { Если (персонаж.здоровье_меньше_трети) персонаж.спрятаться(<параметры>); <…> } } Если (персонаж.вооружён_оружием_ближнего_боя) { Если (персонаж.моё_расстояние_до_врага > персонаж.радиус_действия_оружия) { <……> |
Жёсткая шаблонная логика поведения компьютерных оппонентов даже при кропотливой и подробной реализации вариантов рано или поздно исследуется игроками буквально до последней инструкции - и в ней непременно находятся изъяны. Подобные изъяны и недоработки логики AI нещадно эксплуатируются игроками – и некогда умные действия компьютерного оппонента превращаются в бессмысленную и жалкую возню, способную разве что рассмешить получившего вдруг громадное преимущество игрока.
К тому же, в ряде игр реализация и доводка до ума полноценной системы ветвлений для логики компьютерного оппонента невероятно сложна. Так, к примеру, дела обстоят в стратегических играх – живые игроки подчас, нестандартно используя способности тех или иных подразделений, подбрасывают AI весьма непростые задачи. Хитроумные же схемы, разработанные живым человеком или даже целым сообществом, способны порой и вовсе “сломать шаблон” поведения даже самому проработанному AI на основе системы ветвлений.
Спасти от этого могут либо очень подробные структуры самих ветвлений с элементом случайности производимых действий, либо переход к качественно новому механизму функционирования игрового искусственного интеллекта.
В целях увеличения эффективности компьютерного оппонента, придания его действиям разнообразия и до определённой степени разумности, уже достаточно давно применяются такие подходы, как создание AI на основе конечных автоматов, разнообразных недетерминированных методов, создаются и обучаются даже
полноценные нейронные сети!
Некоторые из этих методов являются излишне сложными для небольших проектов в части реализации и доводки, а получаемый на выходе результат без соответствующей оптимизации может быть хуже, чем у классических схемных решений.
Потому ниже с примерами будут рассмотрены два предлагаемых мною метода реализации простейшего AI на основе табличных схем, а также более продвинутый метод – использование марковских цепей дискретного времени.
Одномерная табличная схема “стимул-реакция”
В первом приближении простейшая модель поведения животного может быть рассмотрена как совокупность стимулов – внешних или внутренних механизмов и раздражителей, оказывающих влияние на внутреннее состояние его нервной системы – и непосредственных ответных реакций на них. Так, испытывающее сильный голод животное займётся поисками пищи, чем-то испуганное – примет меры для защиты или бегства - и так далее. Если животное находится под воздействием нескольких стимулов одновременно – например, хочет есть и спать – будет выбран имеющий высший приоритет или просто наиболее сильный.
Подобным образом может принимать решение и несложный искусственный интеллект. В рамках данной схемы предположим, что AI управляет действиями некоего персонажа или существа, противостоящего игроку – например, дракона.
Для осуществления работы данной схемы составим набор стимулов, которые могли бы руководить классическим сказочным драконом:
- Интерес
- Агрессия
- Осторожность
- Голод
- Усталость
- Страх
которого будет изменяться от 0 (стимул отсутствует) до 1 (максимальная сила воздействия).
Составим таблицу, характеризующую дракона на момент встречи с игроком:
| Стимул | Интерес | Агрессия | Осторожность | Голод | Усталость | Страх |
| Сила воздействия | 0.53 | 0.15 | 0.08 | 0.33 | 0.29 | 0.11 |
| Стимул | Интерес | Агрессия | Осторожность | Голод | Усталость | Страх |
| Сила воздействия | 0.02 | 0.15 | 0.12 | 0.33 | 0.29 | 0.11 |
(для простоты предполагаем, что вид
игрока не оказал на дракона никакого эффекта, однако вид его оружия
заставил дракона несколько насторожиться)
В таком случае, наиболее сильным стимулом для дракона становится Голод, и игрок, являющийся для дракона потенциально съедобным, будет им атакован: | Стимул | Интерес | Агрессия | Осторожность | Голод | Усталость | Страх |
| Сила воздействия | 0.02 | 0.85 | 0.12 | 0.33 | 0.29 | 0.11 |
| Стимул | Интерес | Агрессия | Осторожность | Голод | Усталость | Страх |
| Сила воздействия | 0.02 | 0.31 | 0.12 | 0.33 | 0.47 | 0.54 |
Скорость изменения силы воздействия стимулов, в свою очередь, задаётся разработчиком в соответствии с характеристиками и даже с характером конкретного
противника: задав высокую скорость роста Страха, можно легко создать оппонента-труса, предпочитающего спасаться бегством при первом же ранении;
установив скорость небольшой или нулевой, можно создать полную его противоположность. Также, населяя виртуальный мир животными, можно, к примеру,
заранее задать самке кабана, охраняющей своё потомство, заведомо завышенную Агрессию (при встрече с нею игрок будет сразу же атакован), а лесному оленю – высокое значение Осторожности (чуть заслышав игрока, тот бросится бежать, забыв о прочих своих делах).
Подобная гибкость даёт возможность разработчику достаточно легко и свободно настраивать поведение персонажей, управляемых AI. К тому же, список стимулов можно расширять почти неограниченно, а сами значения сил их воздействия – связать между собой определёнными закономерностями или внести некую произвольно изменяющуюся поправку, что заметно разнообразит поведение даже, казалось бы, одинаковых существ.
Важное допущение, на котором целиком основана работа данной схемы – AI в каждый момент времени находится в единственном состоянии. Так, в описанном выше примере дракон, обнаружив игрока, стал исследовать его, после чего вступил в бой, а в конце спасался бегством. Все эти состояния должны быть чётко регламентированы на этапе разработки поведения AI и прописаны в коде самой игры.
Табличная схема “стимул-реакция” расширенной размерности
Заметным недостатком рассмотренного выше механизма можно назвать обилие коэффициентов, а также некоторую неопределённость в плане принятия решений. Если значения двух или более сил воздействия различных стимулов оказываются в определённый момент времени достаточно близки или равны, то поведение компьютерного оппонента вдруг может становиться достаточно странным. В любом случае, в действиях подобного AI могут прослеживаться некоторые “импульсивность” и прямолинейность. Так, возвращаясь к примеру с драконом, можно предположить ситуацию, что игрок, нанося дракону ряд несерьёзных ран, заметно повышает силу стимула Страх, после чего тот становится преобладающим - и дракон обращается в бегство. Однако через короткое время величина Страха естественным образом спадёт. Если на этот момент игрок всё ещё будет в поле зрения дракона, то дракон, находясь под действием иных стимулов (например, снова Голод) начнёт новую атаку.
Подобное поведение компьютерного оппонента в некоторых ситуациях совершенно недопустимо. Впрочем, если обилие коэффициентов есть недостаток модели,
являющийся продолжением её достоинств, то прочие проблемы вполне решаемы введением продвинутого механизма принятия решений.
Создадим для этого дополнительную таблицу, которая в дальнейшем и будет использоваться для управления AI. Столбцы этой таблицы обозначим в соответствии с состояниями, в которые AI может перейти. Пример такой таблицы показан ниже:
| Состояния |
Состояние 1
|
Состояние 2
|
Состояние 3
|
...
|
Состояние N
|
| Суммарная сила воздействия совокупного стимула | 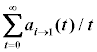 |
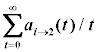 |
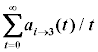 |
|
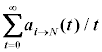 |
Для такой таблицы значение, записанное в ячейке, принадлежащей столбцу j, есть величина, характеризующая общий (т.е. совокупный по всему набору стимулов) стимул для перехода AI из текущего состояния i в состояние j при возможности пребывать в новом состоянии.
То есть, если обозначить стимулы
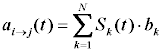 , где
, гдеКак можно заметить, в каждой ячейке таблицы накапливается некоторое усреднённое по времени значение суммарной (за определённый промежуток времени) силы воздействия совокупного стимула. Принятие решений при этом будет осуществляться не просто по текущему превосходящему значению величины силы воздействия конкретного стимула, а по накопленной общей величине. Это значит, что резкое, внезапное изменение того или иного стимула, а также равенство двух и более стимулов не смогут более дестабилизировать работу всей системы в целом.
Предложенное решение, однако, имеет и свои минусы. Устраняя излишнюю “импульсивность”, оно может вносить в процесс выбора решения AI некоторую долю инертности. В ряде ситуаций подобная инертность выглядит как “задумчивость” или даже “тупоумие” со стороны персонажей, подконтрольных компьютерному оппоненту. Отчасти эта проблема решается корректным подбором коэффициентов, а также верного шага по времени между двумя последовательными вычислениями значений ячейки.
Марковские цепи дискретного времени
Более продвинутой схемой табличной логики являются Марковские цепи. При достаточно детальной проработке данный метод позволяет компьютерным оппонентам строить прогнозы развития событий для любых игровых ситуаций, выдвигать собственные оценки и гипотезы насчёт дальнейшего их развития. Этот метод также хорош тем, что в сходных ситуациях AI всегда будет принимать сколько-нибудь различающиеся решения, что делает поведение управляемых им персонажей более живым и непредсказуемым.
Ниже кратко приводятся основные моменты теории вероятности. Те из читателей, кто хорошо помнит этот предмет, могут продолжить чтение с части 3, пропустив следующий подраздел.
Кратко о вероятностях
Согласно теории вероятностей, вероятность наступления какого-либо события – это отношение количества наблюдений, когда ожидаемое событие наступило, к общему количеству наблюдений, когда событие ожидалось. Классический пример – игра в кости. В идеальном случае и при большом числе попыток цифра 5 на кубике будет выпадать, в среднем, один раз на 6 бросков. Записать это можно так:
Величина P, называемая вероятностью, может, при этом, принимать значения от 0 - событие невозможно, до 1 – событие точно совершается.
Рассмотрим более сложный случай – жеребьёвка. Пусть в шапке лежит шесть бумажек, одна из них помечена крестиком. Шестеро игроков вслепую по очереди вытягивают из шапки по одной бумажке и оставляют вытянутую бумажку у себя. Какова же вероятность того, что идущий третьим игрок не вытянет бумажку с крестиком?
Обозначим возможные исходы:
………………………………………………………………
Рассмотрим все варианты развития событий:
• Меченую бумажку вытягивает первый игрок. Вероятность этого
• Меченую бумажку вытягивает второй игрок. Это значит, что данная бумажка не досталась первому игроку; вероятность этого
В шапке при этом останется 5 бумажек.
Если всё сложилось именно так, то вероятность вытянуть меченую бумажку для второго игрока равна
Как же вычислить вероятность события
Для этого требуется перемножить рассмотренную выше величину условной вероятности
В этом случае вероятность того, что игрок три вытянет меченую бумажку, также будет равна нулю.
• Меченую бумажку вытягивает третий игрок. Это возможно только при условии, что игроки один и два вытянули чистые бумажки. Вероятность такого совпадения
Вероятность события
Отсюда можем найти искомую вероятность того, что третий игрок не вытянет бумажки с крестиком:
В качестве любопытного наблюдения можно также отметить, что, в условиях честной игры, совершенно не важна очерёдность, в которой игроки при жеребьёвке тянут бумажки – вероятность получения бумажки с крестиком при изменении порядка никак не изменится.
Таковы основы математического аппарата Марковских цепей.
Марковские цепи дискретного времени
Суть метода
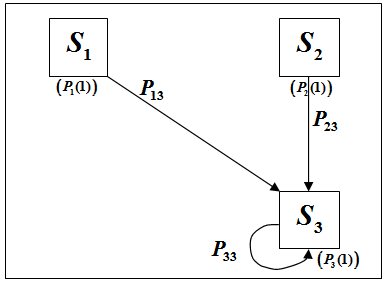
Данный метод основан на оперировании таблицами вероятностей перехода из одного состояния в другое в каждый данный момент времени. Эта таблица или матрица вероятностей, в общем случае, будет иметь следующий вид:
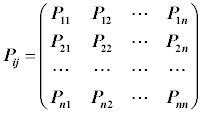
Сама таблица формируется так:
...
| ||||
...
|
||||
...
|
||||
...
|
...
|
...
|
...
|
...
|
...
|
Рассмотрим более подробно реализацию метода на примере несложной практической задачи:
Персонаж, управляемый компьютерным оппонентом, производит по движущейся цели несколько выстрелов подряд.Для простоты скажем, что цель может находиться в четырёх состояниях (каждому из состояний, на практике, можно поставить в соответствие определённый процент “очков прочности”, хит-поинтов цели):
Необходимо определить, какие повреждения цель, вероятнее всего, получит по результатам четырёх последовательных выстрелов.
Повреждения, наносимые цели каждым выстрелом, зависят от ряда условий, которые будем считать случайными; одно – любое - “удачное” попадание способно полностью уничтожить даже совершенно невредимую цель. Промах же, соответственно, никак не изменит состояние цели. В начальный момент времени цель находится в состоянии
Изобразим, для наглядности, схему возможных переходов:
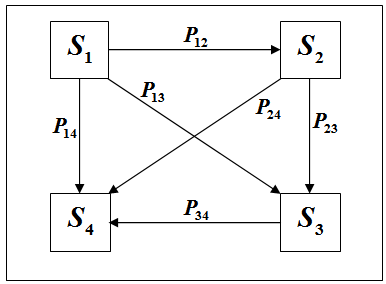
На данной схеме, для простоты, не изображены условия промаха для каждого из состояний
(вероятности и стрелки, началом и концом которых является одно и то же состояние).
и стрелки, началом и концом которых является одно и то же состояние).
Запишем, в соответствие со схемой, матрицу вероятностей переходов,
заполнив её приблизительными значениями вероятностей для каждого из
вариантов. Будем считать, что вероятности здесь соотносятся с точностью
стреляющего, с маневренными свойствами цели и рядом других подобных
параметров: (вероятности
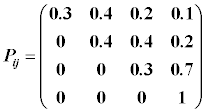
• После первого выстрела эти вероятности, очевидно, изменятся. Из состояния 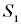 могло произойти 4 перехода – в состояние
могло произойти 4 перехода – в состояние 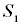 (промах), в
(промах), в 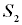 (лёгкие повреждения), в
(лёгкие повреждения), в 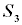 (тяжёлые повреждения) и в
(тяжёлые повреждения) и в 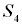 (цель уничтожена). Этим переходам соответствует первая строка матрицы, а сами вероятности нахождения цели в состояниях
(цель уничтожена). Этим переходам соответствует первая строка матрицы, а сами вероятности нахождения цели в состояниях 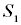 …
…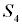 будут иметь после выстрела следующие значения:
будут иметь после выстрела следующие значения:
• Перед вторым выстрелом цель может с некоторой долей
вероятности находиться в любом из четырёх состояний. Значит, для оценки
“результатов” второго выстрела следует рассмотреть все возможные случаи.
Воспользуемся формулой для условных вероятностей.
Так, по результатам двух выстрелов цель может (например) иметь тяжёлые повреждения. Это могло произойти тремя различными способами (см. схему переходов):- Первый выстрел – промах, второй – тяжёлые повреждения.
- Первый выстрел – лёгкие повреждения, второй – тяжёлые.
- Первый выстрел – тяжёлые повреждения, второй – промах.
(сумма всех четырёх вероятностей должна равняться единице – это значит, что нет неучтённых возможностей)
Подобный подход позволяет создавать отдельные подсистемы AI, отвечающие за оценку событий, принятие решений и формулирование управляющих выводов. К примеру, компьютерный оппонент, реализующий подобную схему, может перед боем оценивать вероятность уничтожения игрока имеющимся вооружением раньше, чем игрок уничтожит его, и принимать решение занять оборону или отступить в целях перегруппировки. Произведя несколько выстрелов, он может, вычислив вероятность вывода из строя игрока различными способами (с учётом свойств ландшафта и окружения, если требуется), применить наиболее действенный для данной ситуации. AI может, не зная точного маршрута передвижений игрока, выдвигать несколько “гипотез”, и, основываясь на сведениях о последних точках, где игрок был замечен, вычислять наиболее вероятный маршрут. При этом, что важно, игрок может запутывать преследователей, используя отвлекающие манёвры, уловки - и AI, подобно человеку, пойдёт по ложному следу. Словом, подобные приёмы способны сделать поведение персонажей под управлением компьютерного оппонента гораздо более живым, интересным и правдоподобным.
Кроме того, возможно использование Марковских цепей дискретного времени и на этапе проработки игровой механики – составляя и верно применяя матрицы вероятностей, можно оценить результаты того или иного взаимодействия между объектами игрового мира. Это способно значительно сократить усилия и время на дальнейшую “шлифовку” и доводку игрового процесса.
Весь математический аппарат Марковских цепей, в целом, объёмен и сложен; в статье рассмотрена лишь небольшая, наиболее важная его часть. Схемы на основе Марковских цепей – мощное, но недооцененное средство с широкими возможностями для реализации элементов искусственного интеллекта.
Заключение
Таким образом, табличные схемы – достаточно простой, удобный и гибкий способ реализации ряда элементов искусственного интеллекта. Внедрение подобной схемы в готовое решение AI или разработка AI с нуля на основе изложенных выше принципов позволит создать компьютерного оппонента, адекватно и правдоподобно реагирующего на любые действия игрока.
Предложенные в этой статье варианты – скорее ряд готовых “инженерных рецептов” и рекомендаций, нежели нечто решительно новое в части академических знаний. Читатель, ознакомившись с предложенным в статье, может самостоятельно разрабатывать решения, наилучшим образом подходящие под каждую конкретную его задачу.
Список литературы:
- Беркли Э. Символическая логика и разумные машины. — М.: Мир, 1961. — 258 с.
- Вентцель Е.С. Введение в исследование операций. — М.: Советское радио, 1964. - 388 с.
- Вентцель Е.С. Исследование операций: задачи, принципы, методология. — 2-е изд., стер. — М.: Наука, 1988. - 208 с.
- Маслов В.П. Комплексные марковские цепи и континуальный интеграл Фейнмана для нелинейных уравнений. — М.: Наука, 1976. — 191 с.
- Торндайк Э., Уотсон Д.Б. Бихевиоризм. — М.: АСТ-ЛТД, 1998. — 704 с.
- Трофимов А.И., Егупов Н.Д., Дмитриев А.Н. Методы теории автоматического управления. — М.: Энергоатомиздат, 1997. — 654 с.
- Фабри К. Э. Основы зоопсихологии: Учебник для студентов высших учебных заведений,. — 3-е. — М.: Российское психологическое общество, 1999. — 464 с.
- Фейдимен Д. Радикальный бихевиоризм. Б. Скиннер. — СП-б.: Прайм-Еврознак, 2007. — 128 с.
Если вы ведёте свой блог, микроблог, либо участвуете в какой-то популярной социальной сети, то вы можете быстро поделиться данной заметкой со своими друзьями и посетителями. Для этого воспользуйтесь предлагаемыми ниже кнопками:
Блог: http://romanlovetext.blogspot.com/